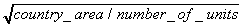The Asian administrative boundaries and population
database was compiled from a large number of heterogeneous sources.
The objective was to compile a comprehensive database from existing
data in a fairly short time period that is suitable for regional
or continental scale applications. The resources available did
not allow for in-country data collection or collaboration with
national census bureaus. With few exceptions, the data do not
originate from the countries, and none of the input boundary data
have been officially checked or endorsed by the national statistical
agencies.
Boundaries
For many of the national boundary coverages that
were used in the construction of this database there was no information
regarding source map scale available. If known, the cartographic
scale of the source maps are indicated in the country documentation
in the appendix. The scale varies between 1:500,000 and 1:5 million;
in the case of the former Soviet Union, the only available boundary
data was a 1:10 million database.
In order to ensure a close match between different
national coverages, and to obtain maximum compatibility with other
standard medium resolution data sets, all national boundaries
and coastlines were replaced with the political boundaries template
(PONET) of the Digital Chart of the World (DCW). The DCW is a
set of basic digital GIS data layers with a nominal scale of
1:1 million scale.
The use of a very detailed international boundaries template for, in some
cases, relatively coarse resolution data is quite misleading,
but was required to ensure a close match between the national
coverages. In any application the smaller cartographic scale (i.e.,
coarser resolution) of the administrative boundary data in comparison
to the international and coastlines template should be kept in
mind.
For a few countries very detailed boundary data were
available for which the spatial referencing information was not
known (Bangladesh, Laos, Indonesia and Vietnam). In light of the
objectives of this project, these were nevertheless incorporated
in order to achieve maximum resolution. Yet, the ad hoc transformation,
projection change and rubbersheeting required to make these data
compatible with the DCW template have no doubt introduced positional
error which may well reach a magnitude in the order of 1-2 km.
In one case, artificial administrative boundaries
were constructed: for Oman detailed population data from
the 1993 census (the first ever in Oman) were available but subnational
boundaries were not. As described in the specific documentation
for Oman, hypothetical subnational boundaries were derived using
Thiessen polygons around the major town in each district.
Population data
With few exceptions, we used official census figures
or official estimates which were taken from national publications
(census reports or statistical yearbooks) or from secondary data
sources (yearbooks and gazetteers). The specific sources are indicated
for each country below. The accuracy of censuses obviously varies
by country. It was beyond the scope of this project to evaluate
the accuracy of every census used, or of any of the official estimates.
This would be possible since most censuses are followed by a post-census
enumeration that provides an accuracy estimate. In countries with
functioning registration systems, population figures reach an
accuracy within a fraction of a percent. In the US, census counts
have been shown to have an accuracy of about 2 percent. With few
exceptions, the accuracy of Asian censuses is likely to be considerably
lower.
Since census taking is irregular in many countries,
the data for some countries are quite old. For several nations
data from the early eighties were the only available source of
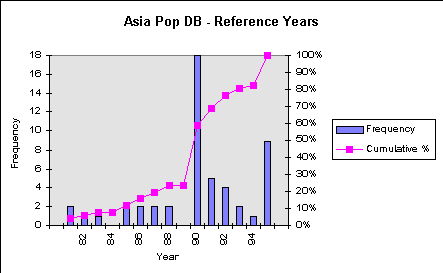
subnational population figures. The following figure shows the
distribution of reference years in the database. For about 25%
of the countries, the reference year is 1988 or earlier. It is
important to note that this distribution and the average year
(1990) are biased upward by those countries for which no subnational
data were available in which case the 1995 UN figures were used.
In order to maximize comparability across national
boundaries, all district-level population figures were projected
to 1995. The volume of papers and monographs on population projection
methods in the demographic literature is very large. It is matched,
however, by the number of publications that emphasize the continuing
inability of these methods to accurately forecast population figures
over more than very short time periods (see the interesting discussion
in Cohen, 1995).
For this project, a simple mathematical trend forecast
was used. In contrast to previous estimates for the global demography
project, the current figures for each subnational unit are based
for most countries on a district-specific intercensal growth rate
between the last and the next to last enumeration. The intercensal
growth rate was calculated as
,
where r is the average rate of growth, P1and P2are the population totals,
for example, in the first and second census, and t is the
number of years between the two enumerations. The 1995 estimate
was then derived using:
.
See, for example, Rogers (1985). For predictions
over only a few years, mathematical trend projections are usually
fairly accurate, and the specific type of function used has little
influence on the results (Cohen 1995). A more elaborate estimation
approach such as the cohort survival method would result in more
reliable estimates, but the data requirements for this technique
(age and sex distribution as well as age specific birth, death
and migration rates) were far beyond what was possible in this
project. Given the method used for the population forecasting,
the characteristics of the available source data obviously have
a significant impact. An example will illustrate this point.
For Israel, population figures were available for
a number of years in the Statistical Yearbook of Israel 1991.
The following table shows the total population for the six districts
of Israel for four recent years. The last three columns show total
population estimates for 1995 based on average annual growth rates
between each of the first four years and 1990. The choice of the
growth rate obviously has a considerable effect on the resulting
estimate. Even allowing for the special nature of Israel's population
dynamics due to the country's immigration policy (the most likely
explanation for the high 1989-90 rates), the fact that the estimates
are strongly dependent on the available input data becomes clear.
Furthermore, the quality of the source data is likely to be lower
in most countries of Asia, and in many cases the data are older.
District
Total Population (`000)1
Avg. Annual Perc. Growth Rate
Resulting Estimates for (`000) 1995 based on rate for
1985
1987
1989
1990
85-90
87-90
89-90
85-90
87-90
89-90
Jerusalem
506
533
556
578
2.66
2.70
3.88
660
662
702
Northern
707
732
763
805
2.60
3.17
5.36
917
943
1052
Haifa
593
601
613
656
2.02
2.92
6.78
726
759
921
Central
889
928
970
1032
2.98
3.54
6.20
1198
1232
1407
Tel Aviv
1015
1027
1044
1095
1.52
2.14
4.77
1181
1218
1390
Southern
511
526
542
574
2.33
2.91
5.74
645
664
765
1Data Source: Central Bureau of Statistics (1991), Statistical Abstract
of Israel 1991, Jerusalem.
This example shows that the 1995 population estimates
are at best a rough estimate which should be interpreted within
wide confidence margins. In general we can expect the reliability
of the 1995 estimates to be lower, the longer the census upon
which they are based lies back - that means the confidence intervals
around the point estimates become increasingly wider over time.
The data for some countries for which data were available for
the early eighties only, need to be regarded as a best-guess only.
The figures included in the database are directly taken
from the estimation and thus show more significant digits than
is justified by their accuracy. During data manipulation and processing
one should preserve all significant digits, but for presentation
purposes, the figures should be rounded to reflect the uncertainty
of the data. Even the use of population numbers to the nearest
thousand in the above table is clearly optimistic.
Given the limited amount and quality of the base
population data, we checked the resulting total national population
figures against a standard benchmark, the regularly published
population estimates produced by the Population Division of the
United Nations (World population prospects: The 1994 revision,
UNPOP/DESIPA, New York, 1994). In the summary table in the appendix,
both the total estimated population and the UN figure for 1995
are presented. Obviously, the UN data are by themselves associated
with a considerable amount of uncertainty since the estimates
are based on conditional forecasts that make a number of assumptions
regarding the most recent and future fertility, mortality and
migration rates. They are also based, for the most part, on official
census figures which sometimes prove to be highly unreliable (Nigeria
being a notorious example). In cases where our estimate was considerably
different from the UN estimate, the intercensal growth rates were
adjusted uniformly such that the resulting estimate was equal
to or close to the UN estimate. Typically this is the case where
the latest available population figures were very old, or where
a country experienced significant reductions in fertility in recent
years that are not sufficiently reflected in the population dynamics
between the last two censuses (e.g., Thailand). The adjustments
are indicated in the specific country documentation below.
UN population figures were used in two additional
cases: (1) for countries for which no subnational boundaries or
data were available (e.g., Singapore, Bahrain, Lebanon), we used
the 1995 population estimate from the UN Population Division;
(2) for countries for which census figures were available for
only one point in time or for which the next to last census was
too long ago, we applied the average annual national growth rate
between the census year and 1995 as indicated in the UN World
Population Prospects to each administrative unit resulting in
a uniform adjustment of population figures across the nation.
Given our limited knowledge about the accuracy of
the input data, it is impossible to make an objective assessment
of data quality. The development of a qualitative index of boundary
and population data quality was considered. However, such an
index would be associated with considerable subjective judgment.
Any question "how good are the data?" is incomplete
since we also have to ask "for what purpose?"
Data that are clearly inappropriate for high resolution applications
at the province or sub-province level, are still sufficiently
accurate to be used in regional or continental scale applications
(the prime motivation for this project), or for the visualization
of spatial patterns in a country. Thus, we only provide some
informal summary measures in the table below, and refer to the
individual country documentation that provides all known details
about the lineage of the data (admittedly, this knowledge is too
often very limited). The user can consider this information to
make his or her own decision about whether the data are appropriate
for the specific tasks.
As in previous databases of this nature, we included
two useful summary measures of data resolution in the summary
table in the appendix:
Mean resolution in km =
i.e., the length of a side of an administrative unit, if all the units were square.
Mean population per unit = total_national_population / number_of_units..
These two measures complement each other well. In
countries where large areas are uninhabitable, the mean resolution
in km gives a biased impression of available detail. In such cases,
the number of people per unit is a more meaningful indicator.



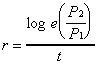 ,
,
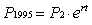 .
.